【講演会】「モダンな」可視化アプリケーション開発とはどのようなものか?を開催しました
2017年7月8日(土)、TECHPLAY SHIBUYA(旧dots.)をお借りして、E2D3もくもく会と講演会を開催しました。
カリフォルニア大学サンディエゴ校医学部に所属するエンジニアであり、オープンソースのネットワーク可視化ソフトウェアCytoscapeのコア開発者である大野圭一郎さんをお招きして、『「モダンな」可視化アプリケーションとはどのようなものか?』と題した講演をしていただきました。

メインの講演は17:00からの予定でしたが、機材不調で参加者LT大会を先に実施。今回は総勢8名の方がLTをしてくださいました。発表者リストは以下の通り。参加者LTの振り返りは、メイン講演サマリーの後に続きます。
- Vue.jsとmapboxを利用した位置情報可視化アプリケーション開発 by Kaito Kinjo
- データビジュアライゼーションから考える「料理とは何か?」 by 出雲翔
- 日用消費財の営業戦略運営で期待されるデータ可視化 by 篠原剛
- E2D3の品質管理について by Junichi Watanuki
- データの可視化とチームの進化 by 吉田 雅史
- スポーツデータビジュアライゼーション〜東京五輪に向けて〜 by 多田哲馬
- D3.js バッドノウハウ集 by 清水正行
- Grimoire.jsとデータビジュアライゼーション by 城山賢人
内容が濃く多岐にわたるLTで脳も身体も限界まで達したところで、メイン講演が始まりました。
スピーカーの大野圭一郎さんは、カリフォルニア大学サンディエゴ校医学部に所属するエンジニアで、オープンソースのネットワーク可視化ソフトウェアCytoscapeを開発された方です。Cytoscapeを使うと、遺伝子ネットワーク、ソーシャルネットワークが可視化できます。このソフトウェアを使って、塩基配列、たんぱく質、遺伝子の機能などのデータを統合・解析・可視化し、主に基礎医学研究者に対してデータを提供されています。研究者へのインタビュー、論文執筆、学会発表、ワークショッップの講師など様々な業務をされています。
最近では、①階層化された遺伝子群の可視化、②技術の古くなったアプリケーションの拡張、③良い技術を使いまわせるようにすること、をしていらっしゃいます。遺伝子オントロジーを機械的に生成するDeep Cell(仮)を新しいPJとして着手しています。
本日は、複雑なデータセットを可視化するアプリケーションのデザイン手法や実際の設計についてお話し頂きます。
【モダンなデータ可視化アプリケーション開発とは?】
テーマの一部でもある「モダンなデータ可視化アプリケーション開発とは?」という問いに答える前に、まず大野さんから質問。次のうちで現在使っているツールはありますか?
- D3.js ver.4
- react
- BABEL
- webpack
- npm
大野さんはモダンを定義するにあたって、使用技術、開発スタイル、設計という三つの観点を挙げていらっしゃいました。使用技術が古くても開発スタイル(GitHub利用)や設計(データモデル、レンダリングレイヤーの分離)が新しいもの(Cytospaceが良い例)があることがわかりました。
モダンなデータ可視化アプリケーションの一つの定義として、以下の5点が挙げられます。
- モジュール化されている
- よく知られた可視化のパターンや原則を利用している
- アプリケーションの基本設計として、データとUIの設計が構造化されている
- データの管理に一定のルールを持つ
- テスト可能
モダンであることは、特定の最新の技術を使うことではなく、アプリケーションの構造デザインと使用するテクノロジーの組み合わせが実現するものなのではないかと、大野さんはおっしゃっています。
とはいえ、無駄な労力を使わないツールを選ぶことも能力の一つ。モダンなデータ可視化アプリケーションの開発をする上で必要なツールについて、「現時点での」と条件を付けた上で、大野さんは以下のようにご教示くださいました。
- 言語: ES2015以降
- パッケージマネージャー: npm
- ビルドツール: webpack3
- コンポーネント化: React
- 可視化: D3.js, 好みのレンダリング技術
これらが組み合わされば、①トランスパイル、ミニファイ、テストなどの自動化、②モジュール化とそれに伴う再利用性の向上、③コンポーネントベースでの可視化機能設計が出来ます。少し前に、「フロントエンド界隈が複雑化しすぎ問題」がありましたが、最低限、npm(依存管理)、webpack(ビルドとタスク実行)、BABEL(互換性のための変換)があれば良く、基本的なツールの提供機能にそれほど変化はないのではないかとまとめています。
【複雑なデータセットを可視化するアプリケーションのデザイン方法】
使用するテクノロジーには大きな制限やルールがないことがわかりましたが、アプリケーションの構造デザインはどのように形作れば良いのでしょうか。
データの示し方には、①シンプルなチャート(棒グラフ円グラフ)、②scrollytelling(複数のデータセットを用いてストーリーを構成)、③data dashboard(複数のデータセットを複数の手法で可視化)、④ライブラリ(汎用性を高めて他者が再利用できるように設計してあるコンポーネント)があります。
示し方に応じて必要となるフレームワークは変わってきます。使用するデータと最適な見せ方を明確にした上で、それに応じたフレームワークを選ぶことが重要だと大野さんは言います。
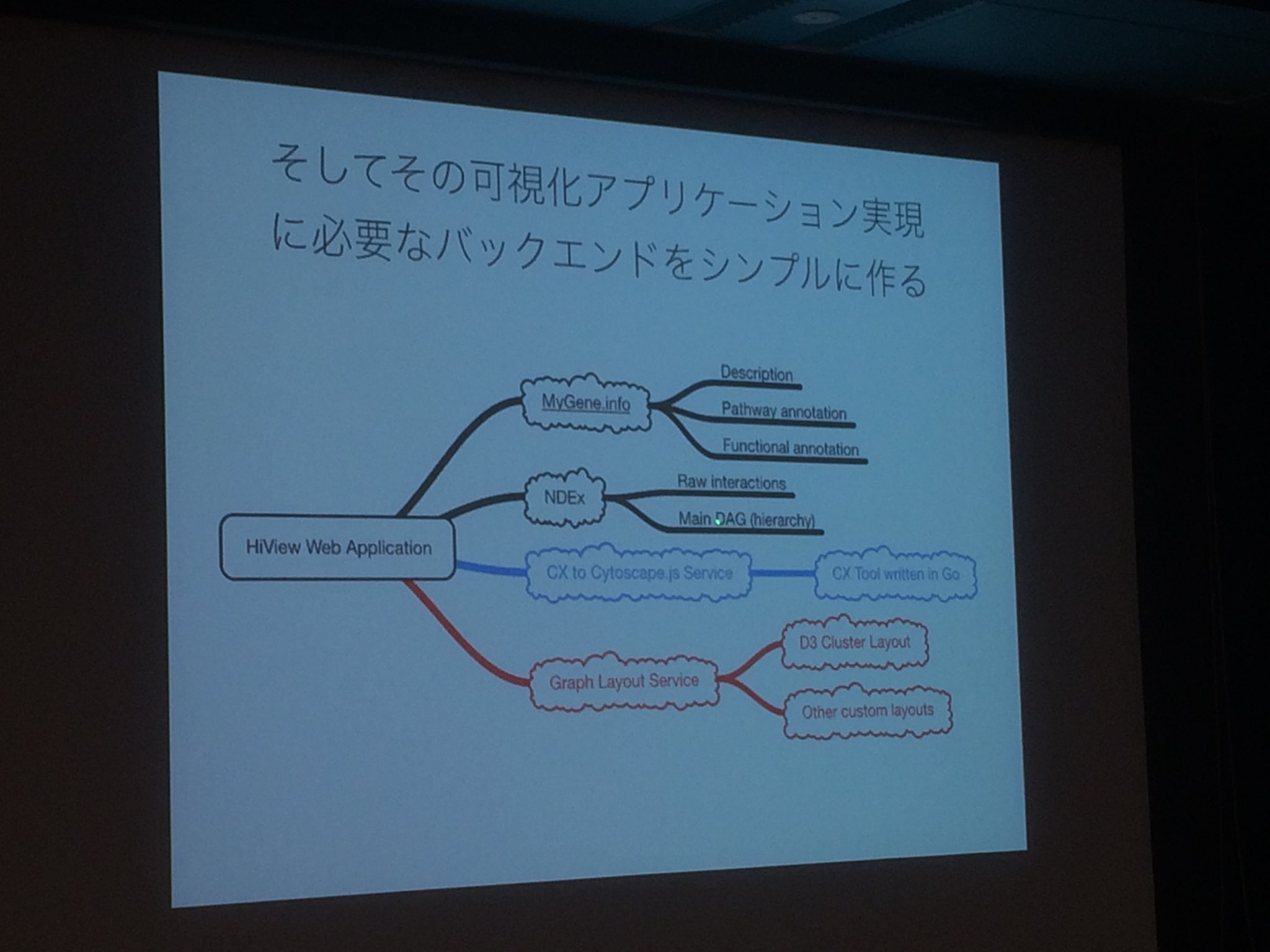
ここで、ダッシュボードの全てをツリーで構成した実際の構造デザイン例を見せていただきました。
実際に使ったデータは、大規模な遺伝子ネットワーク、それらを統計解析し生成したオントロジー、遺伝子アノテーションです。すなわち、階層構造、グラフ(ネットワーク)、テーブルデータを互いに関連するものとして可視化し、ユーザーの選択に基づいて複数のビューを連動させていくということを行います。
- まず、可視化に必要となる要素をコンポーネントのツリーとして書き出します。
- 次に、そのコンポーネントを作るために必要なデータモデルを考えます。
- 最後に、可視化アプリケーションを実現するために必要なバックエンドをツリーで構成します。
これらのステップは全てツリーで行われました。可視化アプリケーションを実現するにあたり、表示されるものや求められている見え方を整理するためにツリーは重要なツールとなります。
【実際の設計と実装:React + D3を例に】
実装の際に大野さんは、主にReactとD3.jsを使っているそうです。Reactは小さめのフレームワークで且つコンポーネント化することを意識した設計になっています。D3.js、特にversion4は大規模アップデートがされており、可視化のための標準ライブラリとなってきています。

この二つにそれぞれ役割分担をさせ、組み合わせてつかうことでデータ可視化アプリケーションが実装できます。Reactには仮想DOMの管理をさせ、D3.jsは数学用ライブラリとして使います。描画をReactに任せてほぼReactのみで実装する方法もあれば、その逆もあります。実装者の技量、アプリケーションのサイズ、取り扱いデータの大きさなどによってどちらの方法をとるか変わってきます。
かっこつけずに、目的を達成するために必要なものはなにか、一番の近道はなにかを考える必要があります。必要に応じて、バックエンドで処理するようなコードを書いたり、PythonやRの方が得意そうな処理であればそれらでコードを書いた上で呼び出せば良いのです。全てをフロントエンドで処理する必要はありません。バックはDockerで、フロントはnpmで、パッケージしていけばシンプルにいつでも再利用可能です。

大野さんのお話は、極めて実践的な大学の講義のようでした。参考文献として、Learning Reactをあげていただきました。
今回の講演で、「モダンな」可視化アプリケーション開発について、以下のことがわかりました。
- メンテナンス可能な構造である
- 特定のテクノロジーに縛られすぎていない
- React+D3.jsの組み合わせが開発のための現時点での最適と考えられる選択肢である
大野さん、参加された皆さん、お疲れさまでした!
質疑応答の時間もたっぷりとりました。一部をご紹介します。
Q. バックエンドはシンプルに、とのことでしたが大量のデータを処理するためのデータストアは必要だと思いますが、よく使われるミドルウェア、あるいはサービスはありますか?
A. Elastic Search 等
Q. 新しい技術の導入の判断基準は?日本だと声の大きい人の意見がそのまま通ってしまうこともあるが?
A. 米国ではある程度ドキュメントがしっかりしていて、ジュニアプログラマーが作れるか(に仕事を頼めるか)が判断基準。英語版の書籍が出た時点で技術を評価してみようかという話になる。
Q. ネットワーク分析による可視化を行った後の解釈や説明を行う際の工夫や注意点など、心がけるべきことは?自身の経験(ツイッターつぶやきデータの可視化等)上、ネットワークの可視化を行い、見せても「ふーん。すごいね。」程度で終わることが多いので。
A. アイキャッチはよく作るが見栄えが良いのと使いやすいのは違う。「だから何?」と言われないためには、サーチ、フィルタリング、インタラクティブ等の機能で使いやすさの向上が大事(サブグラフ発見、他データのオーバーレイ等)。KEGG等の人力レイアウトも。
LTのまとめ
1. Vue.jsとmapboxを利用した位置情報可視化アプリケーション開発 by Kaito Kinjo
Kinjoさんは、株式会社ナイトレイのWebアプリケーションエンジニア。inbound insightの開発を手掛けていらっしゃいます。リリース当初はjQeuryなどを使っていましたが、いまはVue.jsとMapbox押し。PHPエンジニアが多いので、今後はLarabelを使っていきたいと考えているそうです。HTMLを編集せずに移行しやすいのがVue.js。GISの世界をブラウザで実現できると感じていらっしゃいます。会場からは、「inbound insightすてき!」、「mapbox使ってかっこいい地図かけそう」などといった声が上がりました。
2. データビジュアライゼーションから考える「料理とは何か?」 by 出雲翔
ご自身はビックデータを扱うデータサイエンティストである出雲さん。料理=10種類の食材を組み合わせるもの、と仮定した上で、Flavor Network理論を実際にTensor Boardで可視化してみました。理論によれば、ビールとミルクは相性が良いそうです。データだけで見るとコーヒーとビールはテイストが少し似ていることが、その原因のよう。データ可視化によって、料理のプロ/天才のひらめき以外の方法で、料理のイノベーションが起きるかもしれませんね。出雲さんは、データビジュアライゼーションは直感的な理解を得らえる手法と考えていらっしゃいます。他にも、食材間の距離を計算して、その国らしさを算出して可視化するなどのプロジェクトを試みていらっしゃいます。
3. 日用消費財の営業戦略運営で期待されるデータ可視化 by 篠原剛
=このコンテンツは当日ご参加いただいた方のみお楽しみ頂けました=
4. E2D3の品質管理について by Junichi Watanuki
Watanukiさんは、E2D3では主にアプリケーションの品質管理を担っていただいているエンジニアです。オープンソースで様々な人が参加するE2D3では、品質管理の方針として「とりあえず初めて触った人がクリックをしていくだけでそれなりに可動を確認できるようにすること。」を決めています。2016年4月にwatanukiさんを中心として始まったE2D3品質向上プロジェクトにおける進め方や困った点についてお話しいただきました。スライドは、オープンソースの品質管理の参考になるかもしれません。
5. データの可視化とチームの進化 by 吉田 雅史
吉田さんは、人材派遣会社でマーケティングのためのデータ分析をするエンジニア。脱エクセルを目指して、PHPとMySQLとJavascriptでWebアプリケーションを構築。人間によるミスや手作業によるスピード感のなさを解消させました。
チームにエンジニアが入ることで、欲しいものをチームで一から作り上げていく結束感を得られたと言います。共同作業によりアナリストとエンジニアとの信頼関係が構築され、その結果データが民主化(だれでもいつでもどこでも見られる)され、チームメンバーが自らの主体的なアクションでデータを活用できる環境が実現したそうです。技術が味方になることによってチームの意識が向上していく様子を感じられました。
6. スポーツデータビジュアライゼーション〜東京五輪に向けて〜 by 多田哲馬
=このコンテンツは当日ご参加いただいた方のみお楽しみ頂けました=
7. D3.js バッドノウハウ集 by 清水正行
=このコンテンツは当日ご参加いただいた方のみお楽しみ頂けました=
8. Grimoire.jsとデータビジュアライゼーション by 城山賢人
城山さんは現役の大学生で、grimoire.jsを作った方です。webと連携したデータビジュアライズの可能性や波動方程式のビジュアライズについてお話しいただきました。Three.jsとgrimoireの違いについては、前者が3Dエンジニアによる複雑なコードで書かれている印象があるのに対し後者はHTMLでかける点が特徴となっているそうです。